SentimenAnalisis adalah jenis
natural language yaitu pengolahan kata untuk melacak mood masyarakat tentang
produk atau topik tertentu.Analisis sentimen, disebut opinion mining. Definisi
Sentiment Analysis (G.Vinodhini, M.Chandrasekaran 2012).
Analisis sentimen yang kelompok
kami buat merupakan proses klasifikasi dokumen tekstual ke dalam dua kelas,
yaitu kelas sentimen positif dan negative. Topik yang diambil yaitu mengenai
pornografi. Sumber yang dipilih untuk mendapatkan data tersebut dari social
media yaitu Twitter. Twitter merupakan salah satu sosial media yang banyak
digunakan oleh masyarakat luas untuk memposting tweet mengenai berbagai macam
hal. Tidak jarang kita menemukan akun-akun yang memposting hal-hal yang tidak
seharusnya disebar luasnya seperti pornografi.
Pengerjaan program menggunakan
bahasa R. Bahasa R (juga dikenal sebagai GNU S) adalah bahasa pemrograman dan
perangkat lunak untuk analisis statistika dan grafik. R dibuat oleh Ross Ihaka
dan Robert Gentleman di Universitas Auckland, Selandia Baru, dan kini
dikembangkan oleh R Development Core Team, di mana Chambers merupakan
anggotanya. R dinamakan sebagian setelah nama dua pembuatnya (Robert Gentleman
dan Ross Ihaka), dan sebagian sebagian dari permainan nama dari S. (Wikipedia)
Berikut langkah-langkah yang
dilakukan untuk menganalisis sentiment tentang pornografi pada twitter:
I. Mendapatkan
API Twitter
a. Login
ke akun twitter terlebih dahulu
c. Klik My
apps

d. Klik
Create New App

e. Membuat
application isi nama, deskripsi, website, dan callback URL. Pada name isi nama
aplikasi, pada description isi bebas, dan website isi url website jika tidak
memiliki website isi dengan website bebas tetapi valid. Untuk Callback URL
kosongkan. Kemudian klik “Yes, I agree”.

f. Selanjutnya,
pilih Keys and Access Tokens untuk mendapatkan akses API Twitter. Setelah itu
kita medapatkan kode yang akan digunakan diantaranya Cosumer Key (API Key),
Cosumer Secret ( API Secret ), Access Token dan Access Token Secret.
II Program Sentiment Analysis dengan Bahasa R
1. Buka R
lalu install package diantaranya twitteR, plyr, dan stringr
install.packages("twitteR")
install.packages("plyr")
install.packages("stringr")
|
2. Menambahkan
library-library yang dibutuhkan, dengan cara menggunakan perintah library(‘nama
library’).
(twitterR)à package yang
menyediakan ases ke API Twitter sehingga kita dapat melakukan crawling data di
Twitter menggunakan R.
(plyr)à package untuk melakukan
split data.
(stringr)à package ini berguna
untuk membersihkan dan mempersiapkan data dan menangani masalah string yang
umum sehingga menghasilkan string yang lebih bersih. Perintah yang digunakan
seperti pada gambar berikut :
library(twitteR)
library(plyr)
library(stringr)
|
3.
Mengisi dan mendeklarasikan api_key, api_secret,
access_token, dan access_token_secret yang nilainya diambil dari apps twitter
yang sudah dibuat sebelumnya di atas, kemudian variable-variabel tersebut
digunakan untuk men-setup oauth pada twitter, seperti pada gambar di bawah ini:
api_key
<- ""
api_secret
<- ""
api_token
<- ""
api_token_secret
<- ""
setup_twitter_oauth(api_key,
api_secret, api_token, api_token_secret)
|
4.
Fungsi scan() berfungsi untuk memindahkan semua
kata yang berada di dalam file.txt. File.txt dibagi menjadi 2 yaitu positif dan
negative.
pos
= scan('D:/KULIAH/SEMESTER 8/DeepLearning/positive.txt', what='character',
comment.char=':')
neg = scan('D:/KULIAH/SEMESTER
8/DeepLearning/negative.txt', what='character', comment.char=':')
|
5.
Kemudian menggunakan suatu algoritma dari
Jeffrey Brean analyzing. Score.sentiment merupakan fungsi yang memiliki
parameter tweets, pos.words, dan neg.words. Kemudian memanggil library plyr
untuk menghandle list, stringr. scores = laply (tweets, menjalankan function
yang dideklarasikan di atas).
score.sentiment
= function(tweets, pos.words, neg.words)
{
require(plyr)
require(stringr)
scores
= laply(tweets, function(tweet, pos.words, neg.words) {
|
6.
Mengubah huruf menjadi huruf kecil agar lebih
mudah dalam pencariannya dengan perintah :
tweet
= tolower(tweet)
|
Memecahkan kata menjadi perkata
dan dimasukkan ke dalam list dengan perintah :
word.list
= str_split(tweet, '\\s+')
|
Mengubah
list ke dalam vektor
words = unlist(word.list)
|
7.
Selanjutnya, membandingan kata-kata yang didapat
kedalam bentuk negatif dan positif
pos.matches = match(words, pos.words)
neg.matches = match(words, neg.words)
|
8.
Mengubah kata yang yang cocok dalam bentuk True
dan False
pos.matches = !is.na(pos.matches)
neg.matches = !is.na(neg.matches)
|
Nilai dari true/false dianggap 1/0 sehingga
dapat ditambahkan dengan fungsi sum()
score = sum(pos.matches) - sum(neg.matches)
|
9.
Melakukan perulangan score, kemudian
menganalisis kata positif dan negatif.
return(score)
}, pos.words, neg.words)
scores.df
= data.frame(score=scores, text=tweets)
return(scores.df)
}
|
10. Melakukan
pencarian sebanyak 1000 tweet dengan menggunakan bahasa indonesia yang
mengandung kata “bokep” kemudian hasil yang didapat akan dianalisis apakah
merupakan sentimen positif atau negative,
tweets = searchTwitter("bokep",n=1000,
lang="id")
Tweets.text
= laply(tweets,function(t)t$getText())
analysis = score.sentiment(Tweets.text, pos,
neg)
|
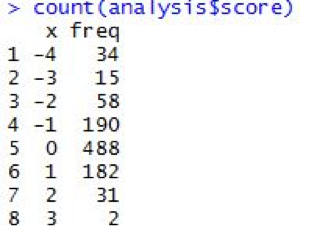
11. Mengitung
banyaknya frekuensi nilai sentimen dengan menggunakan fungsi count(). Kemudian
hasil tersebut dianalisis dan ditulis pada file.csv dengan nama Pornografi.csv.
count(analysis$score)
|
Hasil yang didapat yaitu nilai sentimen dari -4
sampai 3 dengan jumlah terbanyak terdapat pada nilai -1,0,dan 1 dengan
menghasilkan tweet negatif sebanyak 248, netral 488 dan untuk tweet positif
sebanyak 215. Sehingga dapat diambil
kesimpulan bahwa tweet yang netral lebih banyak dari pada tweet negatif maupun
positif. Dan rentan antara tweet positif dan negatif tidak terlalu jauh tetapi tweet
negatif lebih banyak.
12.
Membuat
data dalam bentuk Histogram dengan menggunakan fungsi
hist(analysis$score).
|
Sehingga
didapatkan hasil histogram seperti di bawah ini:

13. Memindahkan
data tersebut ke dalam bentuk csv dengan menyimpan ke file yang diberi nama
Pornografi.csv ditulis dengan perintah berikut:
write.csv(analysis,
"Pornografi.csv")
|
Hasil yang terdapat pada Pornografi.csv

14. File
positive.txt dan negative.txt
Nama Kelompok:
1. Ade
Rizky Putri 50414195
2. Mona
Sarito Siagian 56414830
3. Rania
Dwi Cahyani 58414924
4. Ridwan
Teharudin 59414324



.jpg)




